skynet 的定时器采用了时间轮设计,可以高效的处理定时调用,本篇会尝试理清楚定时器的设计思路和实现方法。
时间轮算法
时间轮是实现高效率定时器的常见算法。虽然经常被形容的很高大上,但是其实时间轮非常好理解,因为它就是取自生活中的例子。
一个简单的例子,如果要在 2022 年 2 月 22 日 22 点 22 分 22 秒做一件事情,那么首先会看年份是不是对应,年份对应了再看月份,月份对应了再看几号,一级一级的向下看,直到秒也可以对应的上,这时候就是要做这件事情了。
可以看到如果是参考现实计时法的时间轮的话,那实现的其实就是一个类似闹钟的功能。当有需要定时执行的事件时,将它加入到目标时间对应的事件队列中。然后每秒执行一次时间累计,不断累加时间。每次累加时间以后,检查当前时间对应的事件队列,如果不为空,则依次执行。
与另一种常见的定时器实现算法最小堆比较,时间轮算法最大的好处是其加入一个新定时事件时的复杂度是 O(1) 的,删除一个事件虽然不是 O(1) 但是大概率也比最小堆要快一些。
用法
skynet 只提供了创建一个定时事件的接口 skynet.timeout,并没有取消这个事件的接口。通过调用 skynet.timeout(ti, func) 即可启动一个定时调用。
因为没办法取消定时,但是有时候又确实需要取消,所以 skynet 的文档中给了一个通过修改闭包函数变量把 func 置空的操作。虽然不是真正的从时间轮中移除,但是也算是一份折中的实现。
|
|
实现
时间轮结构
虽然上面举例使用的是现实中钟表的例子,但是实际上时间轮的实现基本不会是类似钟表的设计,因为在代码中,使用准确的日期其实并不便于计算。
skynet 的实现是一个分层时间轮,一共分了五层。最接近要执行的时间点在 near 里,其余的分层在 t 里,有 4 层。每一层用链表实现,事件执行时从头部取,增加事件时从尾部增加。
因为存在并发的情况,所以时间轮在修改的时候是需要加锁的。这里还是采用了 skynet 中常见的自旋锁来处理。
|
|
增加定时事件
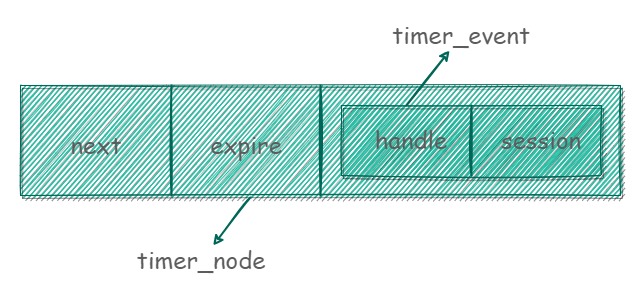
timer_node 结构体用来保存单个定时事件,它是每个定时队列的组成部分。timer_event 用来保存发起定时事件的源服务 handle 和与定时事件绑定的 session 这两部分数据。
|
|
当调用 skynet.timeout 的时候,会向时间轮中加入一个定时节点。处理过程中会首先创建一个 timer_event 结构的变量,然后调用 timer_add 创建一个 timer_node 结构变量,并且把 timer_event 变量的内存直接追加到了 timer_node 变量的内存后面。timer_node 的 expire 会设为 timer.time + 定时的时间。
增加定时节点时,首先要做的是找到合适的定时队列。skynet 一共为队列分了五层,以到期时间距离当前的时间偏移量计算,分别时如下五档。
| 过期时间 | 分层 | 差异位 |
|---|---|---|
| 0 - 255 | near | 0-8 bit |
| 256 - 16383 | 0 | 9-14 bit |
| 16384 - 1048575 | 1 | 15-20 bit |
| 1048576 - 67108863 | 2 | 21-26 bit |
| 67108864 - 正无穷 | 3 | 27-32 bit |
查找适合队列的时候是用 (A | mask) == (B | mask) 的方式计算的,比计算两数相减差值比较上下限要快一点。确定一个时间应该在哪个队列中的方法是,从 0-8 bit 开始比较目标时间和当前时间,如果差异在 0-8 bit 内,则说明距离当前时间不超过 255 秒,则应该放在 near 层中。如果不在当前层,则将掩码左移 6 位继续比较两个值。如果前四层都确定不了的话,则把剩下的全部加到最后一层中。
找到了合适的队列以后,直接把 timer_node 链接到 link_list 的最后即可。
更新时间
timer 线程会每隔 2.5 毫秒更新一次时间。由于 skynet 定时器的最小精度是厘秒,也就是 10 毫秒,所以并不是每次调用的时候都会真正触发时间更新。
当可以触发时间更新时,会计算当前时间和上次时间的偏移量,然后为每个偏移量调用 timer_update 更新定时器。虽然理论上来说不太可能连续多次触发,但是为了防止特殊情况造成的定时被忽略,所以要对每个偏移量执行 timer_update 操作。
更新时间的时候,需要检查是否要移动分层队列中节点的层级。这个并不是每次都要检查,而是每当时间轮的计时累加了 256 次以后才会检查一次。相当于是产生了一次进位,进位以后,当前时间在下一层对应的队列中的节点要被移动到 near 里。
为了便于理解,这里举例说明一下进位操作。比如当前的 T->time 为 511,当前在 near 队列中的数据为 [256, 511],此时再次累加,T->time 变为 512,这时一个 near 单位也就是 256 被处理完毕了,这个时候就要把 [512, 767] 的数据从分层队列中移除,加入到 near 队列中。这部分数据就在第 0 层的 2 节点中,通过将 (time » 8) & 63 即可计算得出。
执行事件
执行事件的时候通过 time & 255 即可拿到当前时间对应的事件链表,如果事件链表不为空,则从头到尾依次对事件调用 dispatch_list 即可。在 dispatch_list 中,timer 线程会拿到一开始加入定时事件时保存的源服务的 handle 和关联的消息 session,向源服务发送一条有对应 session 的消息即可,定时事件的回调函数会在后面被 worker 线程调用。
执行事件本身并没有什么复杂的地方,但是看源码会发现,skynet 在一次 timer_update 里面执行了两次 timer_execute 方法,第一次是在 timer_shift 之前,第二次是在 timer_shift 之后。第二次调用很正常,没什么疑问,但是第一次的调用可能会有点疑惑的地方。
之所以要在 timer_shift 之前也调用一次,是为了处理在上一次 timer_update 之后,到这次 timer_update 之间,加入的 timeout 为 0 的事件,如果没有在 timer_shift 之前的 timer_execute 调用,则这部分事件会被漏掉。
但是,其实如果是通过 skynet 提供的接口创建的定时事件的话,应该是用不到前面的那一次 timer_execute 的,因为 skynet 提供的接口的入口是 skynet_timeout,在这个里面当 time <= 0 时,已经过滤掉了这部分的调用,没有经过定时器,而是直接向源服务发送了触发的消息。那么为什么还要保留这个前置调用呢,这里有一个 issue 说了这个原因,timer 不需要关注 skynet 的用法实现。