Lua 是动态类型语言,变量本身不带有类型,有值了才有类型。当前版本的 Lua 中有八种数据类型,分别是 nil,boolean,number,userdata,thread,string,function 和 table,本篇会分析这些数据类型的实现。
TValue
Lua 中不管是什么类型的值,在 C 层都是用同一个 TValue 结构体变量表示的。这样的实现与为不同数据类型定义不同的结构体相比,可以统一处理接口。
|
|
可以看到 TValue 中的结构很简单,只包含了一个宏定义 TValuefields,它里面又包含了一个表示值数据的 value_ 和一个表示值类型的 tt_ 。
value_ 是一个 union Value 联合体变量,它可以表示 Lua 中所有类型值的数据,不同字段对应的类型注释中已经给出,其中所有需要进行 GC 的数据类型的指针都会保存在 gc 字段中。
tt_ 是一个 unsigned char 类型,它的不同位表示了不同的涵义,如图所示。
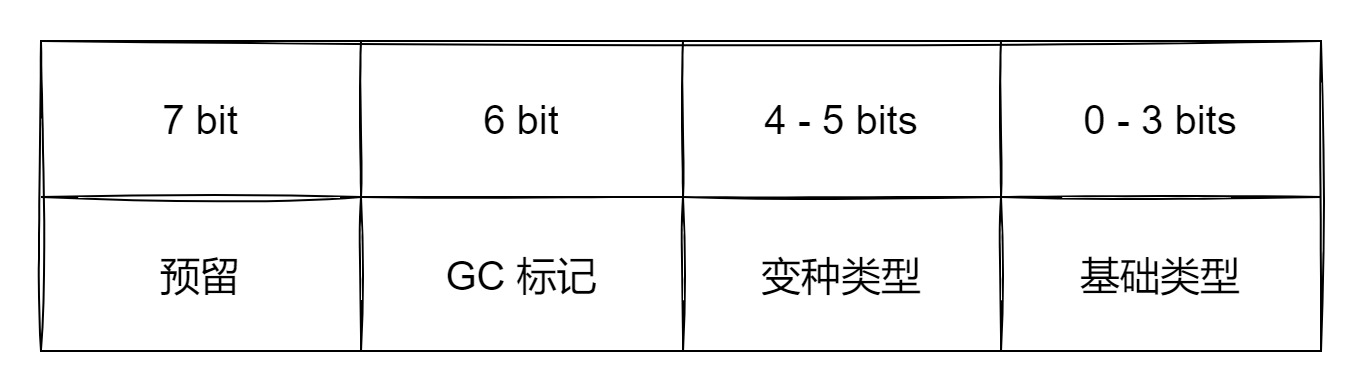
可以看到值的类型由两部分组成,一部分是表示基础类型,比如数字类型就是 LUA_TNUMBER,还有一部分表示变种类型,Lua 中叫 variant,比如数字类型又分成了两类,整数和浮点数,分别用 LUA_VNUMINT 和 LUA_VNUMFLT 表示。下面是全部的基础类型。
|
|
GCUnion && GCObject
在了解 GCObject 之前首先要看一下 GCUnion 这个联合体,它是所有 GC 对象真正保存的位置。在 GCUnion 中,有一个 GCObject gc 的字段,它并不真正代表某一种类型,而是一个抽象的公共字段,来提供类型转换。
|
|
需要 GC 的值虽然有各自的结构,但是对外的时候都是统一以 GCObject 为标准的。GCObject 中包含了三部分的内容,next 是整个 GC 链表的一部分,所有需要 GC 的对象都通过 next 连接了起来。tt 又是数据类型,它跟上面的 tt_ 的用法是一样的,只不过它里面表示的是 GC 对象的类型。marked 用于在 GC 阶段的标识。
|
|
Lua 中定义了很多 GCUnion 到 GCObject 之间互相转换的方法。gco2xx 用来将 GCObject 转为目标类型的 Lua 变量,obj2gco 用来将 Lua 变量转为 GCObject 类型。
|
|
创建 GCObject
可以通过调用 luaC_newobj 接口创建一个 GCObject 变量。它会首先为 GCObject 分配所需大小的内存,然后把 GCObject 的 marked 标记为白色,保存数据类型 tt,最后将自己加入到全局的 global_State 的 allgc 链表的最前面。
nil
nil 在 Lua 中表示空,因为没有值的缘故,它不需要在 Value 中有对应的字段,只要正确设置了它的类型 tt_ 即可。同时在判断值是否为 nil 的时候,直接判断类型即可。
它的基础类型都是 LUA_TNIL,有三个变种类型,分别用在三种不同情况下。
- LUA_VNIL 的 variant 字段为 0,表示这个值是一个空值。
- LUA_VEMPTY 的 variant 字段为 1,表示这是 table 中的一个空 slot 值。
- LUA_VABSTKEY 的 variant 字段为 2,表示这是索引 table 中一个不存在的 key 的返回值。
boolean
boolean 在 Lua 中有 true 和 false 两个值,这里也是没有保存值,而是直接把两种值保存为了两个变种类型。
它的基础类型是 LUA_TBOOLEAN,变种类型有两种。
- LUA_VFALSE 的 variant 字段为 0,表示 false。
- LUA_VTRUE 的 variant 字段为 1,表示 true。
number
数字的基础类型为 LUA_TNUMBER,有两个变种类型,分别代表了整数和浮点数。
- LUA_VNUMINT 的 variant 字段为 0,表示整数。
- LUA_VNUMFLT 的 variant 字段为 1,表示浮点数。
数据保存在 union Value 中,整数使用的是 long long 类型的 i 字段,浮点数使用的是 double 类型的 n 字段。
userdata
Lua 中的 userdata 分为两类,lightuserdata 和 userdata,其中 lightuserdata 是指内存不需要 Lua 管理的指针,userdata 是需要 Lua 负责管理内存的数据指针。
在基础类型定义中,lightuserdata 被定义为了 LUA_TLIGHTUSERDATA,userdata 被定义为了 LUA_TUSERDATA,虽然分了两个基础类型,但是在 Lua5.4 中的注释里提到了,应该把 lightuserdata 看作是 userdata 的一个变种类型,只是为了兼容性才保留了两个基础类型。
lightuserdata 因为不需要保存数据,所以只保存一个指针变量即可,上文提到的 union Value 中的 p 字段就是用来保存 lightuserdata 的指针的。
userdata 需要管理数据,相比 lightuserdata 它需要额外创建一个 Udata 变量用来保存自己的数据,同时它属于需要 GC 的类型,会通过 luaC_newobj 进行创建。
|
|
thread
thread 在 Lua 中用来指代协程,所有协程的类型都是 LUA_TTHREAD,只有这一个基础类型。变种类型也只有一个 LUA_VTHREAD,它的 variant 值为 0。
协程在 Lua 中是 lua_State 结构体的变量,由于它不仅仅是一个简单的数据类型,还跟 Lua 的虚拟机有很大关系,所以不在这里做展开了,后面会专门开一篇写这个。
string
字符串的基础类型为 LUA_TSTRING,有两个变种类型,分别代表了短字符串和长字符串,当字符串长度小于等于 40 个字节的时候,属于短字符串,反之则属于长字符串。
- LUA_VSHRSTR 的 variant 字段为 0,表示短字符串。
- LUA_VLNGSTR 的 variant 字段为 1,表示长字符串。
结构
|
|
短字符串与长字符串使用同一种结构体表示。除了所有 GCObject 都有的 CommonHeader 以外,extra 在短字符串中表示是否是保留字,在长字符串中表示是否已经计算过了哈希值。shrlen 表示短字符串的长度,hash 表示本字符串的哈希值,union u 中的 lnglen 表示长字符串的长度,hnext 用来当作短字符串哈希桶的链表指针,contents 保存了字符串的内容。
全局字符串表
Lua 将短字符串进行了内化处理,相同内容的字符串只会保存一份。在全局的 global_State 中有一个哈希桶用来保存全部的短字符串指针,它的结构如下。
|
|
它的 nuse 表示的是当前哈希桶中总共的元素个数,size 表示的是哈希桶的长度。
全局字符串表会在 luaS_init 中被初始化,它的初始长度是 128,给哈希桶分配内存以后,会调用 tablerehash 填充哈希桶。
tablerehash 是用来执行哈希桶的 rehash 的,在需要修改哈希桶的长度的时候就会执行,它会遍历之前所有字符串,把它们按新的长度重新计算在哈希桶中的位置。
创建字符串
luaS_newlstr 是创建字符串变量的接口,不管长字符串还是短字符串都通过这个函数创建。它在实现的时候通过字符串长度判断,如果长度小于等于 40 则调用 internshrstr 创建一个短字符串,反之则调用 luaS_createlngstrobj 创建一个长字符串。
不管是 internshrstr 还是 luaS_createlngstrobj,在处理完自己特化的工作以后,最后都会调用到 createstrobj 来创建一个字符串变量,它会首先计算出本变量所需的全部内存大小,然后调用上文提到的 luaC_newobj 创建一个 GCObject 出来,通过 gco2ts 把它转为 TString 结构,使用 hash 字段保存它的哈希值,把 extra 字段设为 0,并且会在 contents 最后补上一个 ‘\0’ 表示结束。
短字符串
短字符串在创建的过程中,会修改全局字符串表,首先拿到 global_State 的哈希桶变量 strt,然后通过 luaS_hash 计算当前字符串的哈希值。这里会发现 global_State 中有一个随机种子变量 seed,它会参与到本进程中字符串哈希值的计算里。
通过将字符串的哈希结果对哈希桶的 size 取模得到目标桶的位置,依次遍历桶中的数据,通过比较长度和数据,查找是否有跟目标字符串一样的字符串,如果找到了,直接返回它的指针即可。如果没有找到字符串,则通过 createstrobj 创建一个字符串变量,然后使用 memcpy 把待创建字符串复制进来。短字符串使用 shrlen 保存字符串长度,使用 union u 的 hnext 保存哈希桶中链表的下一个值。
当需要删除一个短字符串时,除了需要处理内存回收,还要把全局哈希桶中的值也移除掉。移除的时候通过字符串的 hash 值计算出对应的链表,然后需要遍历链表查找字符串,找到以后从链表中移除,并且将哈希桶的 nuse 减一。
长字符串
长字符串在 Lua 中当作普通的 GCObject 处理,在创建的时候,会把字符串的长度保存在 union u 的 lnglen 中。从这里可以看出 Lua 对内存使用的优化是很到位的,如果不是为了内存优化,完全可以把长字符串的长度也保存在 shrlen 中,这里跟短字符串的 hnext 共用一个 union,是为了可以把短字符串的长度类型变为 unsigned char 类型。
长字符串在调用 createstrobj 创建 TString 时,不会计算哈希值,而是把 global_State 的 seed 保存在了 TString 的 hash 字段中。在 TString 创建完成以后,一样使用 memcpy 把待创建字符串的内容复制进来。
长字符串的哈希值只有在需要使用的时候才会通过 luaS_hashlongstr 计算,比如说查找 table 的 key 的时候就会需要字符串的哈希值,计算方法与短字符串一样。在计算哈希之前长字符串的 extra 为 0,表示没有计算过哈希值,并且此时 TString 的 hash 中保存的是 global_State 的 seed,计算完以后,会将 hash 改为保存真正的哈希值,并且将 extra 改为 1 表示已经计算过哈希值,下次需要计算的时候,如果 extra 等于 1,则可以直接返回 hash 中的值了。
比较字符串
在 lvm.c 的 luaV_equalobj 中可以看到,当双方都是短字符串时,比较使用的方法是 eqshrstr,当都是长字符串时,比较使用的是 luaS_eqlngstr 函数。
因为短字符串是内化的,所以 eqshrstr 的实现很简单,直接比较两个参数的内存地址即可,相同短字符串都是引用的同一个 TString 变量,地址相同即相等,反之则不等。
由于长字符串并没有进行内化,所以 luaS_eqlngstr 就麻烦一些,会先比较内存地址,如果不等的话,则比较长度,长度相等再使用 memecmp 比较内容。
保留字符串
Lua 中有一些保留字符串,基本上都是关键字。保留字符串都是短字符串,TString 中的 extra 字段就是用来标识保留字符串的。
保留字符串会在初始化的时候被全部创建,extra 会被顺序递增。同时所有保留字符串都会通过 luaC_fix 将其固定下来,永远不会被回收。
proto
proto 是 prototype 的简写,表示函数原型。它的基础类型是 LUA_TPROTO,只有一个变种类型是 LUA_VPROTO,它本身并不是 Lua 对外提供的一类值,但是它是单独的一类 GCObject,并且也是 function 变量的重要组成部分,所以在 function 之前先讲一下 proto 的结构。
|
|
可以看到 proto 的结构中数据还是比较多的,除了所有 GCObject 都有的 CommonHeader 以外,其余的数据大概可以分为几种类型。
- 参数相关
函数的参数可以包括若干个固定参数和一组不定参数,因为 Lua 规定了固定参数必须放在不定参数之前,不存在交叉的可能性,所以只需要使用 numparams 记录固定参数的个数,使用 is_vararg 来记录函数是否接受不定参数即可。 - 调试信息
debug 接口需要获得一些关于函数的调试信息,比如定义的位置等,这些也都在 proto 结构里。linedefined 记录了函数定义开始的行数,lastlinedefined 记录了函数定义结束的行数,source 记录了源文件的地址。不仅这三个,只要需要,其它变量也可以通过 debug 接口来读取。 - upvalue
函数使用的 upvalue 在一个数组 upvalues 中,同时使用 sizeupvalues 变量记录数组的长度。upvalue 有一个自己的结构体 Upvaldesc,每个 Upvaldesc 由名字 name,是否在栈中的状态 instack,索引 idx 和类型 kind 组成。 - 常量
函数中使用到的常量会保存在 k 中,每个常量使用 Lua 值的 TValue 来表示。k 是一个数组,它的长度保存在 sizek 中。 - 指令码
code 中保存的是函数的指令码,是一个 Instruction 类型的数组,Instruction 本身是 Lua 中指令码的类型,是一个 unsigned int 类型。sizecode 是 code 的长度。 - 调用位置
在 lineinfo 中记录了调用本函数的行数,sizelineinfo 记录了 lineinfo 的长度。 - 子函数
函数中的子函数的原型记录在 p 中,是一个 Proto 指针的数组,它的长度在 sizep 里记录。 - local 变量
函数中的局部变量存放在 locvars 中,它是一个 LocVar 结构的数组,sizelocvars 保存了它的长度。每个 LocVar 变量又自己的变量名,开始生效的点和失效的点。 - 绝对行数
abslineinfo 保存了绝对行数的信息,它是一个 AbsLineInfo 结构的数组,sizeabslineinfo 保存了它的长度。每个 AbsLineInfo 中保存了一个 pc 和一个行数。
function
函数的基础类型是 LUA_TFUNCTION,有三个变种类型。
- LUA_VLCL 表示 Lua 闭包,variant 值为 0
- LUA_VLCF 表示轻量 C 函数,variant 值为 1
- LUA_VCCL 表示 C 闭包,variant 值为 2
三种类型的变量都是使用同一个联合体 union Closure 来表示的。
|
|
Lua 闭包
|
|
每个 Lua 闭包是一个 LClosure 变量,它主要包括了一个函数原型和一个 upvalue 的数组。这个 upvalue 是函数所在位置的 upvalue,要注意跟函数原型所在位置的 upvalue 区分。
UpVal 中值保存的情况有两种,open 和 closed,open 代表的是原值没有被释放的情况,比如当子函数在父函数中运行时,父函数里 upvalue 就是 open 状态,在 open 状态下的 upvalue 并不会保存它的值,而是只使用 TValue *v 保存了一个指针。
closed 代表原值已经被释放的情况,比如子函数被当作返回值返回,然后在外部拿到返回值以后执行的情况,这时候父函数中的 upvalue 已经释放了,不能再保存指针了,要自己保存这个值,此时会被保存在 union u 的 TValue value 中,这也就是常见的可以用闭包实现计数器的原理。
C 闭包
|
|
不管是轻量 C 函数还是 C 闭包,都是使用 CClosure 变量表示。upvalue 全部是由 TValue 的值组成的,不存在用指针的情况。当闭包不需要 upvalue 时,也就是只有函数指针的时候,就是轻量 C 函数了。
table
table 是 Lua 中唯一提供的数据结构,它方便易用,很强大,但是因为把 array 和 hashmap 和在了一起,所以在使用的时候也有很多需要注意的地方。
table 的基础类型是 LUA_TTABLE,它只有一个变种类型 LUA_VTABLE,variant 的值为 0。
结构
|
|
由于在 table 中数组和哈希表的混用,所以在结构体中会包含这两类的数据。
数组部分包括了 array 和 alimit 这两个值,array 是一个 TValue 结构体的数组,alimit 是它的长度上限,不一定是真实的长度。
哈希表包括了 node,lsizenode 和 lastfree 三个值,node 是一个 Node 结构体的数组,lsizenode 是它的长度以 2 为底的对数值,这个值也说明了哈希表的长度一定是 2 的幂,lastfree 指向了哈希表最后一个位置。
flags 是一个 unsigned char 类型的值,它里面的每一个 bit 对应了一种元方法是否存在,1 表示不存在,0 表示存在,同时 bit 7 保存了 alimit 是否是 array 的真实长度。
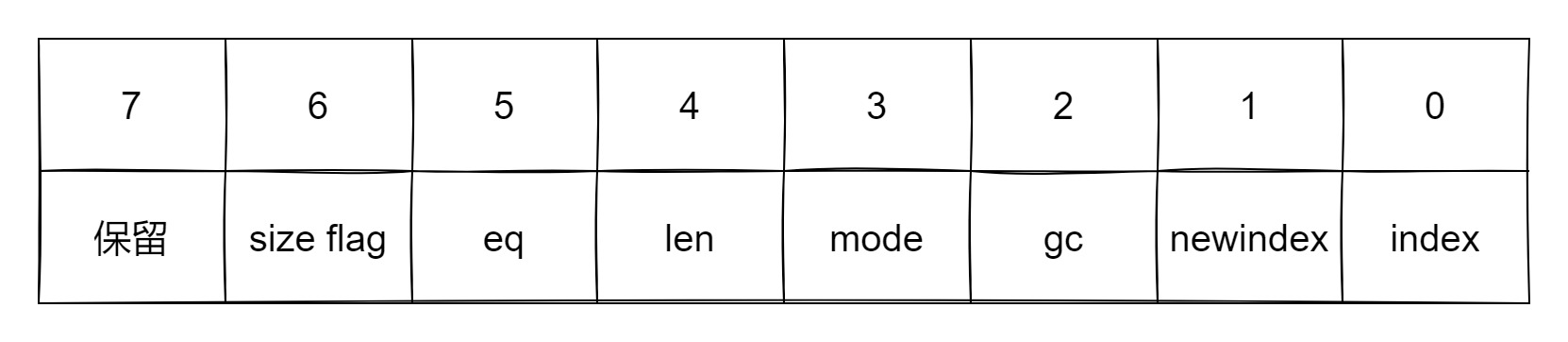 metatable 指向了该 table 的元表,因为元表也是一个 table,所以是一个 Table 结构体的指针。
metatable 指向了该 table 的元表,因为元表也是一个 table,所以是一个 Table 结构体的指针。
哈希表中的每个节点使用 Node 结构体变量表示,它主要分为了两部分,NodeKey u 和 TValue i_val 分别是键值对的键和值。
创建
table 也是 GCObject,所以创建一样使用 luaC_newobj 即可。
对象创建好以后,使用 gco2t 将其转化为 Table 结构的变量,然后将 matetable 设为 NULL,flags 的每一位都设为 1,array 设为 NULL,alimit 设为 0。
还要初始化哈希表,因为一开始哈希表也是空的,所以 node 只需要指向一个占位用的数据即可,Lua 已经创建好了一个静态变量 dummynode 来做这个工作。同时 lsizenode 设为 0,且将 lastfree 设为 NULL,这个可以表示当前使用的是占位 node,方便后续修改。
插入
可以从 C Api 的 lua_settable 入手看一下向 table 中插入一个值的操作。
在设置一个值的时候会先尝试用 luaH_get 去取这个值,如果可以取到的话,则直接修改它就行了,如果取不到,则会首先把 slot 指向用来占位的 static 变量 absentkey,然后调用 luaV_finishset 新增一个值。
在 luaV_finishset 中,会先通过检查 metatable 和 flags 判断 table 是否有 __newindex 元方法,如果没有的话,则使用 luaH_finishset 设置键值对,当 slot 是 absentkey 时,最后会使用 luaH_newkey 创建一个新键值对。
table 的哈希部分解决冲突使用的是开放定址法,有一个 mainposition 的概念,它是通过计算 key 的哈希值,与当前 table 的 lsizenode 取模的出来的。
当通过 key 拿到 mainposition 以后把它保存在 mp 中,然后会判断 mp 是否为空,如果是,则直接把要存的值存在 mp 上即可。如果不是,则会拿 mp 的 key 再去计算一次 mainpositon 保存为 othern,这一步是要判断当前在本位制上的值是不是通过哈希计算来的。
如果是通过哈希计算来的,那就是在本位置上发生了冲突,从 table 的 lastfree 上找到一个空余的点 f,将 f 的 next 设为 mp 的 next,然后将 mp 的 next 设为 f,也就是将 f 链接到了 mp 的后面,最后将值保存在 f 中即可完成。
如果不是哈希计算来的,则说明它是通过 getfreepos 获取的,也就是说它占了我们现在要存的这个 key 的位置,这时候要将它移动到一个新的 freepos 中。因为它的 mainposition 是 othern,所以它现在的位置 mp 是一定在 othern 的 next 链上的,因为它之所以在这里,就是因为跟 othern 的位置冲突导致的。通过 othern 不断向后遍历找到 mp 的位置,然后将 othern 的 next 指向 f,将 *mp 复制到 *f 上,这样就完成了 mp 上的数据转移,然后将数据保存在 mp 上即可。
上面完成的是键值对的新增,至于数组部分,当 key 是一个整数或者是可以转化为整数的浮点数时,在查找 key 的时候会检查 key 的范围,如果 key 在 [1, t->alimit] 中,则直接返回 table 中 array 数组对应的值。如果当前 t 的 array 长度跟 alimit 不等的话,key 等于 alimit + 1,或者 key 小于 luaH_realasize 计算出的值,同样返回 array 中对应的值,并且把 alimit 设置为 key 的值。key 满足在数组部分的时候,直接修改即可。
查询
从 lua_gettable 入手来看一下在 table 中查询一个指定 key 的值的操作。
首先通过 luaH_get 来查找 key 对应的值,如果找到了,则直接返回即可。如果没有找到,则会调用 luaV_finishget,其中会检查 __index 元方法,如果没有该元方法的话,则直接返回 nil 即可。
如果 __index 元方法是一个函数,则调用它,将结果返回。如果是一个 table 则再次使用 luaH_get 尝试返回元表中 key 对应的值。
长度
Lua 中如果对 table 取长度,则只会拿到数组部分的长度,而且如果 table 是数组和哈希表混用的情况下,这个长度可能会有点问题。从 lua_len 入手来看一下取 table 长度的操作。
lua_len 会调用 luaV_objlen 对变量取长度。当类型是 table 的时候,首先会取其 __len 元方法,如果有的话,调用它返回结果即可。如果没有的话,会调用 luaH_getn 来计算 table 的长度。
luaH_getn 的逻辑不长,但是思路比较复杂,Lua 的源码中在函数头给出了 30 行的注释来描述这个函数的作用原理,我尝试把它的大意翻译出来。
尝试找到 table t 的边界,边界是一个整数索引,例如 t[i] 存在但是 t[i+1] 不存在时 i 就是 t 的边界,或者当 t[1] 不存在时 0 就是 t 的边界,当 t[maxinteger] 存在时,maxinteger 就是 t 的边界。
(1). 如果 t[limit] 为空,则它一定有一个在它前面的边界,这时候可以检查 limit - 1 是否存在,如果存在则它是 t 的边界。如果不存在,则在 [0, limit] 上做一个二分查找来寻找边界。这两种情况下找到边界以后都要更新 t 的 alimit 字段。
(2). 如果 t[limit] 不为空,同时数组中有在 limit 之后的数据时,也可以找出 t 的边界。如果 t[limit + 1] 为空,则 limit 就是边界,否则检查数组部分的最后一个元素,如果它是空,则边界一定存在于 limit 和最后一个元素之间,通过二分查找找出来。
(3). 最后一种情况是 t 的数组部分为空,或者它的最后一个元素存在。这两种情况下需要检查哈希部分。如果哈希部分也为空,或者 limit + 1 不存在,则 limit 为边界。否则通过 hash_search 查找在哈希部分的边界。
长度计算非常复杂,所以在开发中永远不要在一个 table 里混用 array 和 map。我觉得 Lua 应该彻底分开这两个东西,混合这两类数据结构,表面上看是降低了门槛,其实我认为反而是提高了隐性的使用门槛。