内存对齐是操作系统为了可以让 CPU 高效读取内存中的数据采用的一种策略,它使得数据在内存中都按一定的规则排列。本篇来解释一下内存对齐。
为什么需要对齐
计算机一般使用字节(byte)作为最小可寻址的内存单位,内存中的每个字节都有一个唯一的数字标识,也就是它的地址了,通常使用一个十六进制的数来表示。如果是占用多个字节内存的数据,则它的地址就是所使用字节中最小的地址。
虽然字节是最小可寻址单位,但是并不是 CPU 的最小读取单位。CPU 从内存中读取数据时需要通过 cache 来作为中间层,会根据目标地址首先在 cache 中找,如果找不到,就会首先从内存加载数据到 cache 中,然后再读取。单次从内存加载到 cache 的数据大小叫做 cache line,它的大小跟硬件有关,一般是 16 到 256 字节。在 Linux 下可以很方便查询这个值,下面给出两种查询方法,可以看到在我本地的平台上这个长度是 64 字节。
|
|
CPU 在使用数据时,需要再次从 cache 中加载内容到寄存器里,这个步骤每次加载的最大长度是一个字长(word size),字长的大小等于我们常说的 xx 位 CPU 的那个数字,常用的 64 位 CPU 的字长就是 64 比特,也就是 8 个字节。当要处理大于 8 个字节的数据时,CPU 需要多次加载处理。
到这里铺垫已经结束了,但是还没有回答真正的问题,因为不管一次读多少,只要按字节来读就可以了,并不需要对齐。比如一个 long 类型变量地址是 6,长度是 8,那 CPU 从 6 开始读 8 个字节就可以了,并不会有什么问题。
真正导致需要内存对齐的原因是,内存条的编址方式导致了 CPU 无法从指定位置开始访问。因为内存条的 IO 采用了多个颗粒并行执行,逻辑上连续的 8 个字节其实是分布在 8 个不同的 bank 上,并行读取可以为内存的访问加速。内存条寻址的规则就是以 8 个字节为单位的,这就导致了 CPU 也只能以 8 个字节为粒度进行读取,且起始地址也要是 8 的倍数。来看一个例子。
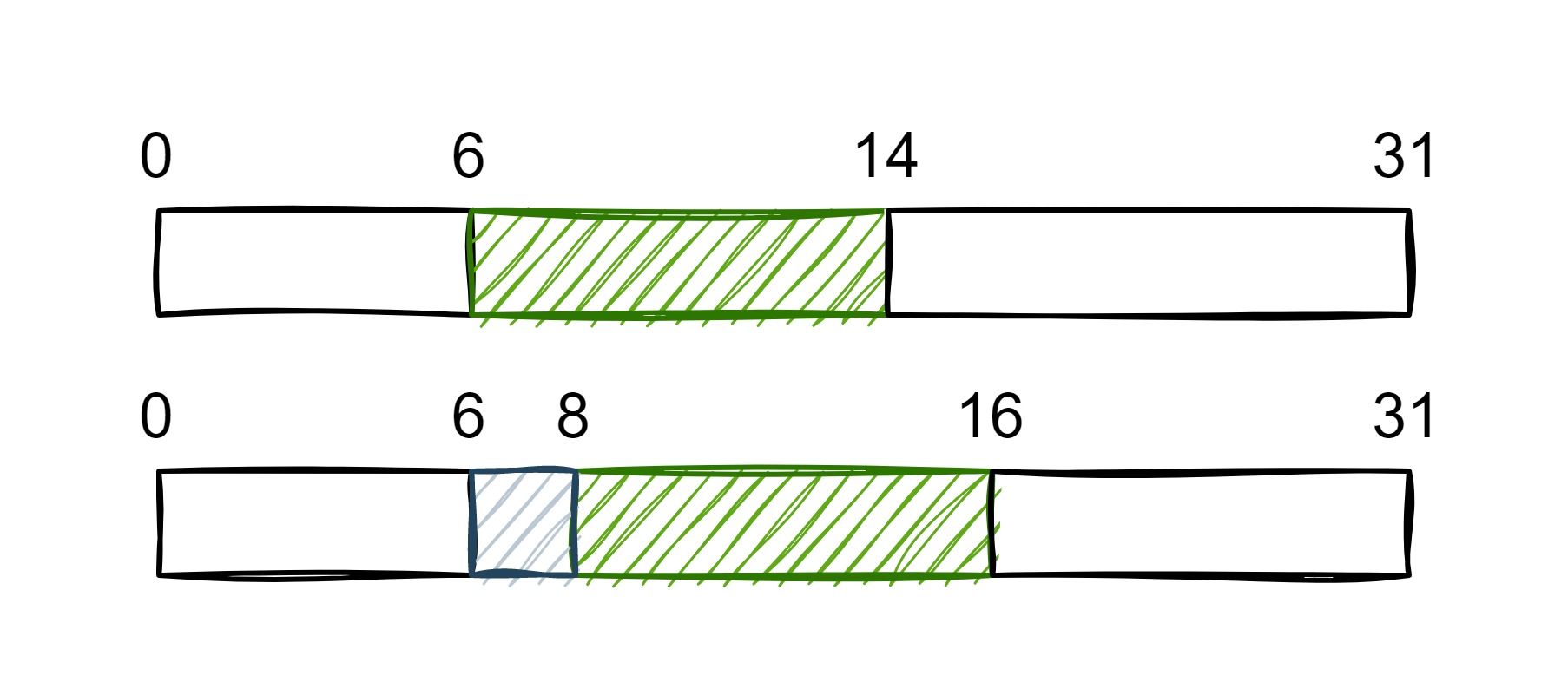
如上图所示,假设一个占用 8 字节的 long 类型整数存放在内存中,如果使用第一张图中的存放方式的话,那么在 64 位环境下,需要读取两次,分别是 0 - 7 字节 和 8 - 15 字节,两次组合才能得到该数字。如果它对齐到 8 的倍数的地址,那么一次读取即可完成。
实现
对齐的规则
内存对齐的规则大概可以总结为四点:
- 对于内置类型,只要它的地址是它长度的整数倍即可。
- 对于 struct,其中的每个数据都要对齐,struct 本身也要向其中最大的那个数据对齐。
- 对于 union,按照其中最长的那个数据对齐。
- 对于数组,无需特殊处理,因为其中每一个数据都对齐了,数组本身就对齐了。
对齐的操作
在 struct 中,如果内存紧密排布可能会出现其中一些数据无法对齐的情况。
|
|
比如结构体 s,如果紧密排布的话,i 占用 0 - 3 字节,d 占用 4 - 11 字节,这样就导致了 d 没有对齐。所以会在 i 和 d 之间增加一个填充部分(padding),长度为 4 字节,使 i 和 d 都对齐。
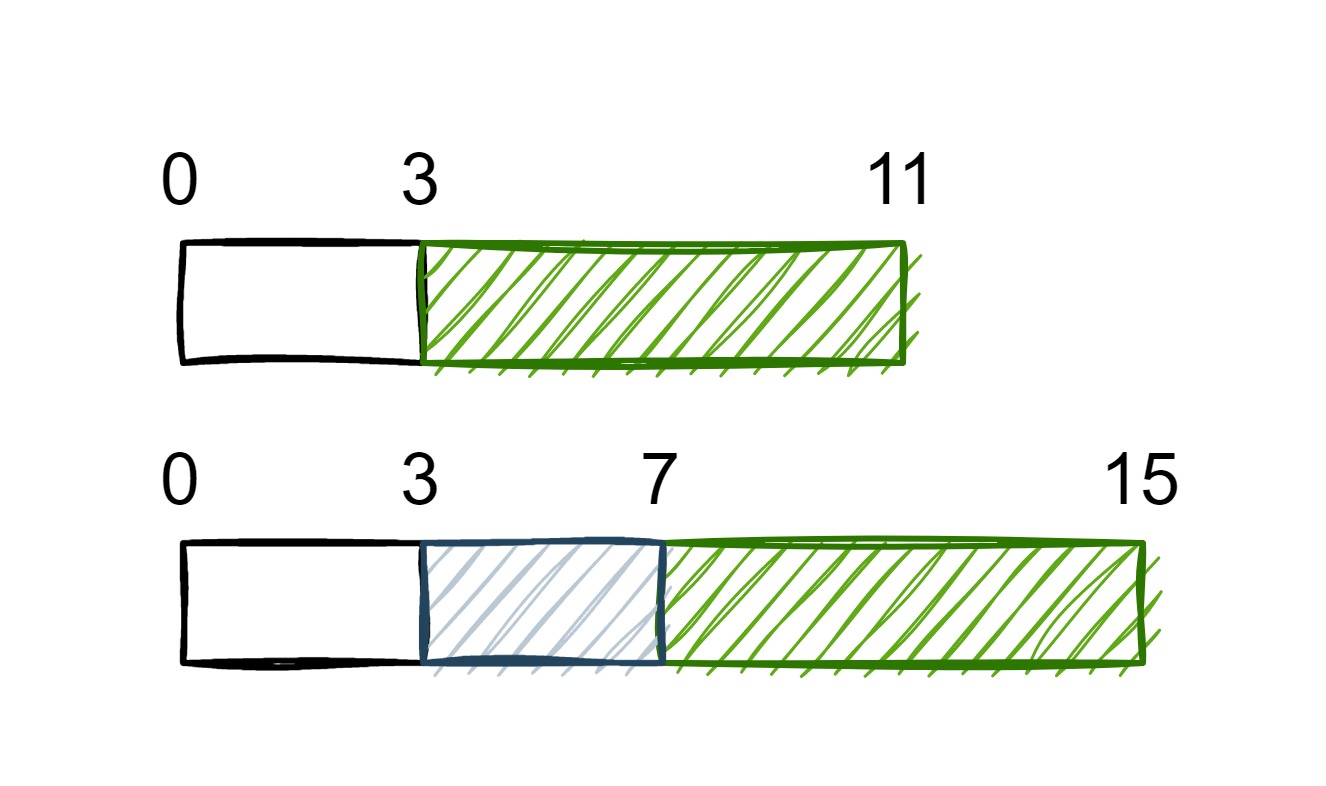
可以看到填充部分的增加使结构体中每一个数据都对齐了,但是也浪费了一部分的内存。当使用 sizeof 查询 s 的长度时,得到的结果是 16 字节。
|
|
如果将 d 和 i 的顺序反过来,情况会有所不同,虽然看起来 d 和 i 都对齐了,但是它本身的长度为 12 字节,没有对 8 字节对齐,需要在它的末尾追加一个 8 字节的填充部分。
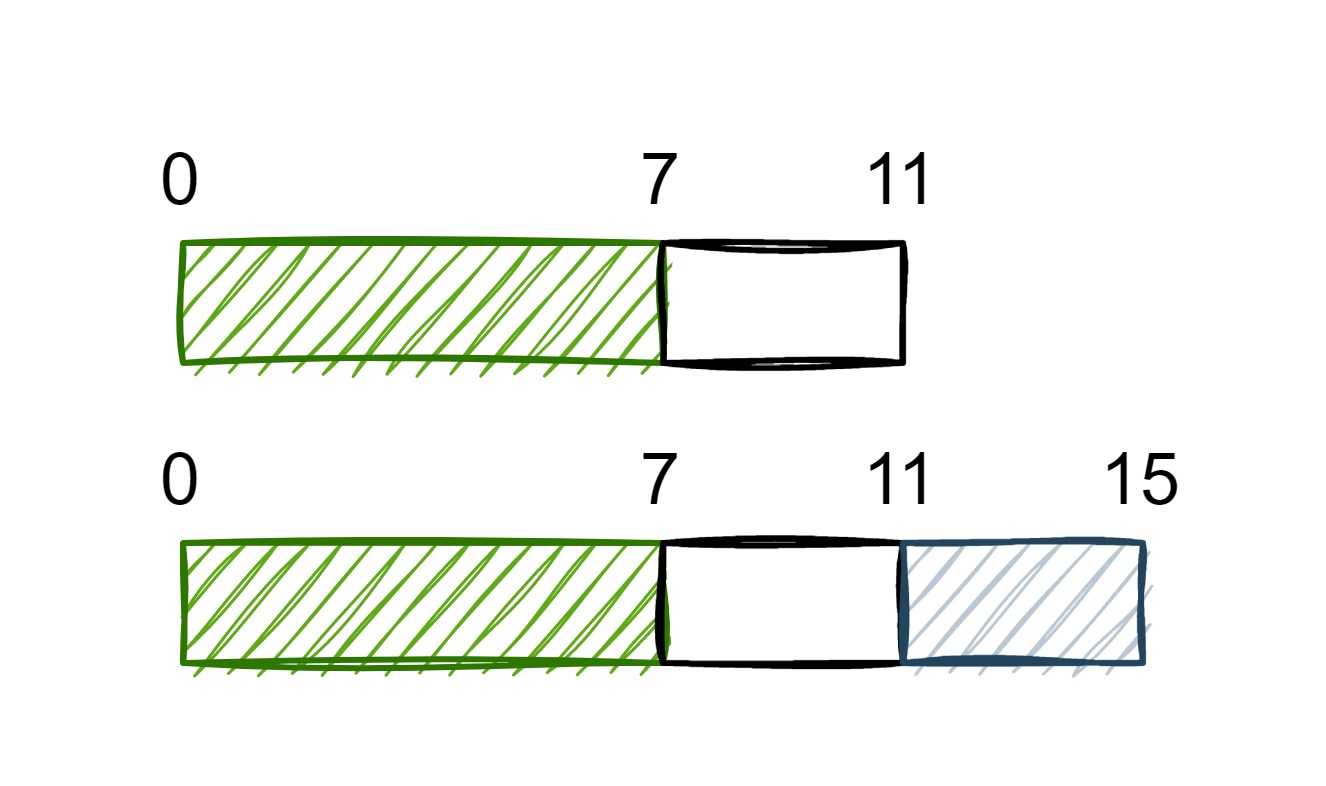
使用 sizeof 查询 s 的长度可以发现它的长度依然是 16 字节。
优化内存占用
可以看到因为填充部分的存在,如果我们设计 struct 时随意写数据的顺序可能会造成一定程度的空间浪费,而当熟悉对齐的规则时就可以排布出一个最省内存的顺序。来看一道 CSAPP 上的题目。
|
|
rec 当前以 8 字节对齐,长度为 56 字节。其中为了让 c 对齐在 b 和 c 之间有一个 6 字节的填充,为了让 e 对齐在 d 和 e 之间有一个 3 字节的填充,为了让 g 对齐在 f 和 g 之间有一个 7 字节的填充,为了让整个 rec 对齐在 h 后面还有一个 4 字节的填充。一共 36 字节的结构,多使用了 20 字节的填充,浪费率比较惊人。下面来重排一下它的顺序。
|
|
经过重排以后,可以发现数据之间已经完全不需要填充部分了,不过因为 rec 要向 8 字节对齐,所以最后的 4 字节填充是必不可少的。重排以后的长度为 40 字节,减少了 16 字节的空间浪费。
我不想对齐行不行
可以看到内存对齐在大部分情况下不管怎么优化,都会浪费一部分空间。它虽然提升了一点内存访问的速度,但是可能很多时候我们并不十分在乎,反而更在意内存的额外占用。
早年间的一些 CPU 是不支持没有对齐的内存访问的,但是在现代 CPU 上已经没有了这个问题,编译器也提供了一些选项可以让我们明确指出不需要内存对齐。
|
|
如果加上了 attribute((packed)),则编译器会使内存紧密排布,去掉所有对齐的优化。这个时候再输出类的长度,可以发现它的长度是 5,就是一个 int 加上一个 char 的长度。如果去掉紧密排布的声明,则类的长度是 8,char 后面会增加 3 个字节的填充。
让类的空间密集排布一定会影响内存的读取效率,但是实际测试一下就会发现,这个影响其实非常非常有限,基本上可以忽略不计了。所以如果对内存占用更敏感的程序,可以主动放弃内存对齐,比如 Redis 的 sds 的结构体就全都是紧密排布的。
指定对齐的字节数
默认情况下类内的对齐是按照本类中最大长度的成员变量对齐的,可以指定让一个类向一个固定的值对齐。
|
|
如果没有指定对齐到 8 字节的话,testc 的长度应该是 (1 + 3) + 4 + (1 + 3) = 12,当指定向 8 字节对齐以后,testc 的长度就是 (1 + 3) + 4 + (1 + 7) = 16。
需要注意的是,指定的长度是整个结构对齐的长度。即使指定了对齐的长度,c1 和 i 之间的填充部分还是只填到 i 长度的整数倍就可以了,只是最后整个 testc 需要对齐的 8 字节的倍数,所以向后补充了 7 个字节。